
科学家们终于对完整的人类基因组进行了测序——并揭示了新的遗传秘密

对人类基因组最后 8% 的测序花费了 20 年时间,发明了读取遗传密码长序列的新技术,该序列由核苷酸 C、T、G 和 A 组成。整个基因组包含超过 30 亿个核苷酸。图片来源:Ernesto del Aguila III,NHGRI
着丝粒周围的重复DNA序列显示了人类遗传变异的历史。
当科学家在 2003 年公布人类基因组的完整序列时,他们有点捏造。
事实上,近 20 年后,大约 8% 的基因组从未被完全测序,主要是因为它由高度重复的 DNA 块组成,很难与其余部分对齐。
但一个成立三年的联盟终于填补了剩余的 DNA,为科学家和医生提供了第一个完整的、无间隙的基因组序列供参考。
新完成的基因组被称为 T2T-CHM13,代表了当前参考基因组 GRCh38 的重大升级,医生在寻找与疾病相关的突变时使用该参考基因组,以及研究人类遗传变异进化的科学家使用。

除其他外,新的 DNA 序列揭示了着丝粒周围区域的前所未有的细节,这是细胞分裂时染色体被抓住并拉开的地方,确保每个“子”细胞继承正确数量的染色体。该地区的变异性也可能为我们人类祖先如何在非洲进化提供新的证据。
“发现这些以前缺失的基因组区域的完整序列告诉了我们很多关于它们是如何组织的,这对于许多染色体来说是完全未知的,”加州大学伯克利分校的博士后研究员 Nicolas Altemose 说。四篇关于完整基因组的新论文的合著者。“以前,我们只是对那里的东西有最模糊的了解,而现在它已经清晰到单碱基对分辨率。”
Altemose 是一篇描述着丝粒周围碱基对序列的论文的第一作者。一篇解释测序是如何完成的论文将出现在 4 月 1 日的《科学》杂志印刷版中,而Altemose 的着丝粒论文和其他四篇描述新序列告诉我们的内容的论文在期刊中进行了总结,全文发布在网上。四篇配套论文,包括一篇由 Altemose 为共同第一作者的论文,也将于 4 月 1 日在线发表在Nature Methods杂志上。
测序和分析是由一个 100 多人的团队进行的,即所谓的Telemere-to-Telomere Consortium或 T2T,以覆盖所有染色体末端的端粒命名。该联盟的所有 22 个常染色体和 X 性染色体的无间隙版本由 30.55 亿个碱基对(构建染色体和我们的基因的单位)和 19,969 个蛋白质编码基因组成。在蛋白质编码基因中,T2T 团队发现了大约 2,000 个新的基因,其中大多数被禁用,但其中 115 个可能仍被表达。他们还在人类基因组中发现了大约 200 万个额外变异,其中 622 个发生在医学相关基因中。
“将来,当某人对他们的基因组进行测序时,我们将能够识别他们 DNA 中的所有变体,并利用这些信息更好地指导他们的医疗保健,”T2T 的负责人之一、高级研究员 Adam Phillippy 说。美国国立卫生研究院国家人类基因组研究所(NHGRI)的研究员。“真正完成人类基因组序列就像戴上一副新眼镜。现在我们可以清楚地看到一切,我们离理解这一切意味着什么又近了一步。”
进化着丝粒
着丝粒内和周围的新 DNA 序列总计约占整个基因组的 6.2%,或近 1.9 亿个碱基对或核苷酸。在其余新添加的序列中,大多数位于每条染色体末端的端粒周围和核糖体基因周围的区域。整个基因组仅由四种核苷酸组成,它们以三种为一组,编码用于构建蛋白质的氨基酸。Altemose 的主要研究包括寻找和探索蛋白质与 DNA 相互作用的染色体区域。

在细胞分裂过程中将染色体拉开的纺锤体(绿色)附着在一种称为动粒的蛋白质复合体上,该复合体在称为着丝粒的位置锁定在染色体上——着丝粒是一个包含高度重复 DNA 序列的区域。比较这些重复序列的序列揭示了突变累积了数百万年的位置,反映了每个重复序列的相对年龄。活跃着丝粒中的重复序列往往是该区域中最年轻和最近重复的序列,并且它们的 DNA 甲基化程度非常低。在两侧活跃着丝粒周围是较老的重复,可能是以前着丝粒的遗迹,最古老的着丝粒离活跃着丝粒最远。研究人员希望新的实验方法能够帮助揭示为什么着丝粒从中间进化,以及为什么这种模式与动粒结合和低 DNA 甲基化密切相关。学分:加州大学伯克利分校的 Nicolas Altemose
“没有蛋白质,DNA 就什么都不是,”获得博士学位的 Altemose 说。在获得博士学位后,于 2021 年从加州大学伯克利分校和加州大学旧金山分校联合获得生物工程博士学位。牛津大学统计学专业。“DNA 是一组指令,如果周围没有蛋白质来组织、调节、修复受损并复制它,就没有人可以阅读它。蛋白质-DNA相互作用确实是基因组调控的所有作用发生的地方,能够绘制出某些蛋白质与基因组结合的位置对于理解它们的功能非常重要。”
在 T2T 联盟对丢失的 DNA 进行测序后,Altemose 和他的团队使用新技术在着丝粒内找到了一个称为动粒的大蛋白质复合物牢固地抓住染色体的位置,以便细胞核内的其他机器可以将染色体对分开。
“当出现问题时,你最终会得到错误分离的染色体,这会导致各种问题,”他说。“如果这种情况发生在减数分裂中,这意味着你的染色体异常可能会导致自然流产或先天性疾病。如果它发生在体细胞中,你最终可能会患上癌症——基本上,细胞有大量的失调。”
他们在着丝粒内和周围发现的是新序列层覆盖着旧序列层,好像通过进化,新的着丝粒区域被反复放置以与着丝粒结合。较老的区域的特征是更多的随机突变和缺失,表明它们不再被细胞使用。动粒结合的较新序列的可变性要小得多,而且甲基化程度也较低。甲基的添加是一种表观遗传标签,倾向于使基因沉默。
着丝粒内部和周围的所有层都由重复长度的 DNA 组成,基于一个大约 171 个碱基对长的单位,这大致是缠绕一组蛋白质形成核小体的 DNA 长度,保持 DNA 包装和紧凑。这 171 个碱基对单元形成了更大的重复结构,这些重复结构串联重复多次,在着丝粒周围形成了一个大的重复序列区域。
T2T 团队只关注一个人类基因组,该基因组是从一种称为葡萄胎的非癌性肿瘤中获得的,该肿瘤本质上是一个拒绝母体 DNA 并复制其父系 DNA 的人类胚胎。这样的胚胎死亡并转化为肿瘤。但事实上,这颗痣有两个相同的父亲 DNA 拷贝——都带有父亲的 X 染色体,而不是来自母亲和父亲的不同 DNA——这使得测序变得更容易。
研究人员本周还发布了来自不同来源的 Y 染色体的完整序列,该序列的组装时间几乎与基因组其余部分的总和一样长,Altemose 说。对这一新 Y 染色体序列的分析将出现在未来的出版物中。
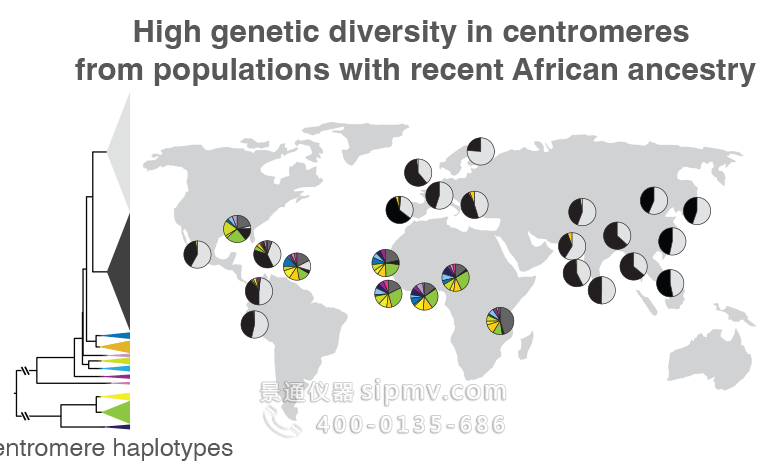
当研究人员比较来自世界各地的 1,600 人的着丝粒区域时,他们发现那些没有近期非洲血统的人大多具有两种类型的序列变异。这两种变化的比例由圆圈内的黑色和浅灰色楔形表示,它们位于地图上每组个体被采样的位置附近。那些来自非洲或其他有很大比例的人最近有非洲血统的地区,如加勒比地区,有更多的着丝粒序列变异,以多色楔形为代表。这种变异可以帮助追踪着丝粒区域如何进化,以及这些遗传变异如何与健康和疾病相关。学分:加州大学伯克利分校的 Nicolas Altemose
Altemose 和他的团队,包括加州大学伯克利分校项目科学家 Sasha Langley,也使用新的参考基因组作为支架来比较来自世界各地的 1,600 个人的着丝粒 DNA,揭示了周围重复 DNA 的序列和拷贝数的主要差异着丝粒。先前的研究表明,当一群古代人类从非洲迁移到世界其他地方时,他们只带走了一小部分基因变异样本。Altemose 和他的团队证实这种模式延伸到着丝粒。
“我们发现,在最近有非洲大陆以外血统的个体中,他们的着丝粒,至少在 X 染色体上,倾向于分成两个大簇,而大多数有趣的变异发生在最近有非洲血统的个体中,”Altemose说过。“鉴于我们对基因组其余部分的了解,这并不完全令人惊讶。但它表明,如果我们想研究这些着丝粒区域的有趣变异,我们真的需要集中精力对更多的非洲基因组进行测序,并完成端粒到端粒的序列组装。”
他指出,着丝粒周围的 DNA 序列也可用于将人类谱系追溯到我们共同的猿祖先。
“当你离开活跃着丝粒的位置时,你会得到越来越多的退化序列,以至于如果你走到这片重复序列海洋的最远海岸,你就会开始看到古老的着丝粒,也许,我们遥远的灵长类动物祖先曾经与动粒结合,”Altemose 说。“这几乎就像一层层的化石。”
长读测序改变游戏规则
T2T 的成功归功于改进的一次测序长 DNA 片段的技术,这有助于确定高度重复的 DNA 片段的顺序。其中包括 PacBio 的 HiFi 测序,可读取长度超过 20,000 个碱基对,准确率高。另一方面,由 Oxford Nanopore Technologies Ltd. 开发的技术可以按顺序读取多达数百万个碱基对,但保真度较低。相比之下,Illumina Inc. 所谓的下一代测序仅限于数百个碱基对。
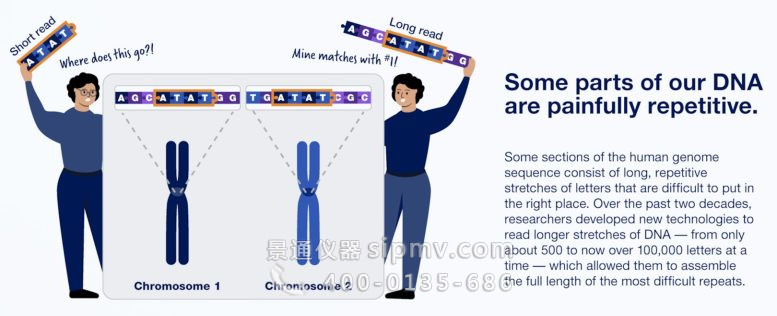
完成人类基因组序列需要 20 年的原因之一是:我们的大部分 DNA 都极其重复。信用:信息图由 NHGRI、NIH 提供
“这些新的长读长 DNA 测序技术简直令人难以置信;它们是这样的游戏规则改变者,不仅因为这个重复的 DNA 世界,而且因为它们允许你对单个长 DNA 分子进行测序,”Altemose 说。“您可以开始以前所未有的分辨率提出问题,即使使用短读长测序方法也是如此。”
Altemose 计划进一步探索着丝粒区域,使用他和斯坦福大学的同事开发的一种改进技术来确定染色体上与蛋白质结合的位点,类似于动粒与着丝粒的结合方式。这种技术也使用了长读长测序技术。他和他的团队在本周发表在《自然方法》杂志上的一篇论文中描述了这项技术,称为长读长测序定向甲基化 (DiMeLo-seq) 。
与此同时,T2T 联盟正在与人类泛基因组参考联盟合作,致力于打造代表全人类的参考基因组。
“我们应该有一个代表每个人的参考,而不是仅仅从一个人类个体或一个葡萄胎(甚至不是真正的人类个体)获得一个参考,”Altemose 说。“关于如何实现这一点有各种各样的想法。但我们首先需要掌握这种变异是什么样子的,我们需要大量高质量的个体基因组序列来实现这一点。”
他在着丝粒区域的工作,他称之为“激情项目”,由博士后奖学金资助。T2T 项目的负责人是加州大学圣克鲁兹分校的 Karen Miga、华盛顿大学的Evan Eichler和 NHGRI 的 Adam Phillippy,他们提供了大部分资金。着丝粒论文的其他加州大学伯克利分校的合著者是生物工程助理教授 Aaron Streets;Abby Dernburg 和 Gary Karpen,分子和细胞生物学教授;项目科学家 Sasha Langley;和前博士后研究员吉娜卡尔达斯。
类似内容推荐
- 科学家在DNA中构建生物阀门以控制细胞信息流
- 饥饿游戏:科学家揭开大脑中饥饿开关的秘密
- 科学家尝试使用核磁共振波谱 (NMR)构建SARS-CoV-2分子的三维结构
- 研究人员已确定了一种控制细胞生长和存活的细胞通讯途径
- 研究发现抗生素可以治疗癌症等人类疾病
- 新发现表明人类细胞可以将RNA序列写入DNA
- 新诊断策略可用来作为帕金森病和其他突触核蛋白病理治疗
- 新基因治疗方法可用于各种电性心脏病和疾病
- 科学家惊讶地发现致命基因已从无害生物转变为致命病原体
- 新算法可以作为分析生物系统模型的更有效方法
- 科学家发现神经免疫相互作用如何燃烧深层脂肪
- 基因分析揭示了无吸烟史人群肺癌的起源
- 科学家首次对人类基因组进行了完整测序
- 科学家实现了微磁体远程控制脑细胞
- 科学家们发现了变异的冠状病毒蛋白复合物
- 基因测序的飞跃将导致改进的个性化医学和对进化的理解
- 新型神经网络模型可预测DNA序列变化
- 科学家创造了由人类细胞制成的“时间机器”来逆转胰腺癌的扩散
- 植物科学家在百里香和牛至等草药中找到抗癌化合物的配方
- 与嗅觉有关的基因可能在乳腺癌向大脑的传播中发挥作用
版权属于:景通仪器 - 国内领先的显微镜与显微数字成像解决方案供应商
转载时必须以链接形式注明作者和原始出处及本声明。
本文地址:http://www.sipmv.com/blog/3375/